Table of contents
Open Table of contents
HTTP/2 与 HTTP/1.1
HTTP 的版本进化看了太多知识点真的很容易晕,平时不太关注,太多真记不住,关注一下最重要的几个点。
| HTTP/1.1 改进的点 | HTTP/1.1 不足的点 | HTTP/2 改进的点 |
|---|---|---|
| 持久连接 在 HTTP/1.0 时期,每进行一次 HTTP 通信,都需要经过 TCP 三次握手建立连接。若一个页面引用了多个资源文件,就会极大地增加服务器负担,拉长请求时间,降低用户体验。 HTTP/1.1 中增加了持久连接,可以在一次 TCP 连接中发送和接收多个 HTTP 请求/响应。只要浏览器和服务器没有明确断开连接,那么该 TCP 连接会一直保持下去。 持久连接在 HTTP/1.1 中默认开启(请求头中带有 Connection: keep-alive),若不需要开启持久连接,可以在请求头中加上 Connection: close。 | 队头阻塞 虽然在 HTTP1.1 中增加了持久连接,能在一次 TCP 连接中发送和接收多个 HTTP 请求/响应,但是在一个管道中同一时刻只能处理一个请求,所以如果上一个请求未完成,后续的请求都会被阻塞。 TCP 连接数限制 浏览器对于同一个域名,只允许同时存在若干个 TCP 连接(根据浏览器内核有所差异),若超过浏览器最大连接数限制,后续请求就会被阻塞。 Chrome 对同一个域名最多允许 6 个连接。 | 多路复用 HTTP/2 允许在单个 TCP 连接上并行地处理多个请求和响应,真正解决了 HTTP/1.1 的队头阻塞和 TCP 连接数限制问题。 |
| 新增 Host 头处理 在 HTTP/1.0 中认为每台服务器都绑定一个唯一的 IP 地址,因此一台服务器也无法搭建多个 Web 站点。 在 HTTP/1.1 中新增了 host 字段,可以指定请求将要发送到的服务器主机名和端口号。 | 头部冗余 HTTP 请求每次都会带上请求头,若此时 cookie 也携带大量数据时,就会使得请求头部变得臃肿。 | Header 压缩 使用 HPACK 算法来压缩头部内容,包体积缩小,在网络上传输变快。 |
| 分块编码传输 在 HTTP/1.1 协议里,允许在响应头中指定 Transfer-Encoding: chunked 标识当前为分块编码传输,可以将内容实体分装成一个个块进行传输。 | 二进制分帧层 在 HTTP/1.x 中传输数据使用的是纯文本形式的报文,需要不断地读入字节直到遇到分隔符为止。而 HTTP/2 则是采用二进制编码,将请求和响应数据分割为一个或多个的体积小的帧。 | |
| 断点续传、并行下载 在 HTTP/1.1 中,新增了请求头字段 Range 和响应头字段 Content-Range。 前者是用来告知服务器应该返回文件的哪一部分,后者则是用来表示返回的数据片段在整个文件中的位置,可以借助这两个字段实现断点续传和并行下载。 | 服务端推送 允许服务端主动向浏览器推送额外的资源,不再是完全被动地响应请求。例如客户端请求 HTML 文件时,服务端可以同时将 JS 和 CSS 文件发送给客户端。 | |
HTTP 缓存策略
HTTP 缓存主要分为强缓存和协商缓存。 强缓存可以通过 Expires / Cache-Control 控制,命中强缓存时不会发起网络请求,资源直接从本地获取,浏览器显示状态码 200 from cache。 协商缓存可以通过 Last-Modified / If-Modified-Since 和 Etag / If-None-Match 控制,开启协商缓存时向服务器发送的请求会带上缓存标识,若命中协商缓存服务器返回 304 Not Modified 表示浏览器可以使用本地缓存文件,否则返回 200 OK 正常返回数据。
流程图

强缓存
Expires
- HTTP/1.0 产物。
- 优先级低于 Cache-control: max-age。
- 缺点:使用本地时间判断是否过期,而本地时间是可修改的且并非一定准确的。
Expires 是由服务端返回的资源过期时间(GMT 日期格式/时间戳),若用户本地时间在过期时间前,则不发送请求直接从本地获取资源。
Cache-Control
- HTTP/1.1 产物。
- 优先级高于 Expires。
- 正确区分 no-cache / no-store 的作用。
Cache-Control 是用于页面缓存的通用消息头字段,可以通过指定指令来实现缓存机制。
- public:所有内容都将被缓存(客户端和代理服务器都可缓存)
- private:所有内容只有客户端可以缓存,Cache-Control的默认取值
- no-cache:跳过当前当前强缓存,客户端缓存内容,直接进入协商缓存阶段。
- no-store:所有内容都不会被缓存,即不使用强制缓存,也不使用协商缓存
- max-age=xxx (xxx is numeric):缓存内容将在xxx秒后失效,只有http1.1可用。
协商缓存
强制缓存失效后,browser携带缓存标识tag向server发请求,由服务器根据缓存tag决定是否使用缓存的过程。 tag分为两种:Last-Modified和ETag,不分上下。
Last-Modified / If-Modified-Since
- 通过资源的最后修改时间来验证缓存。
- 优先级低于 ETag / If-None-Match。
- 缺点:只能精确到秒,若 1s 内多次修改资源 Last-Modified 不会变化。
如果资源请求的响应头里含有 Last-Modified,客户端可以在后续的请求的头中带上 If-Modified-Since 头来验证缓存。若服务器判断资源最后修改时间一致,则返回 304 状态码告知浏览器可从本地读取缓存。
ETag / If-None-Match
- 通过唯一标识来验证缓存。
- 优先级高于 Last-Modified / If-Modified-Since。
如果资源请求的响应头里含有 ETag,客户端可以在后续的请求的头中带上 If-None-Match 头来验证缓存。若服务器判断资源标识一致,则返回 304 状态码告知浏览器可从本地读取缓存。 唯一标识内容是由服务端生成算法决定的,可以是资源内容生成的哈希值,也可以是最后修改时间戳的哈希值。所以 Etag 标识改变并不代表资源文件改变,反之亦然。
扩展
缓存位置
- 从 Service Worker 中读取缓存(只支持 HTTPS)。
- 从内存读取缓存时 network 显示 memory cache。
- 从硬盘读取缓存时 network 显示 disk cache。
- Push Cache(推送缓存)(HTTP/2.0)。
- 优先级 Service Worker > memory cache > disk cache > Push Cache。
最佳实践:
资源尽可能命中强缓存,且在资源文件更新时保证用户使用到最新的资源文件
- 强缓存只会命中相同命名的资源文件。
- 在资源文件上加 hash 标识(webpack 可在打包时在文件名上带上)。
- 通过更新资源文件名来强制更新命中强缓存的资源。
HTTP 状态码
| 状态码 | 含义 | 示例用法 |
|---|---|---|
| 1xx | 信息性状态码 | - |
| 100 | Continue | 服务器已收到请求头,客户端应继续发送请求体。 |
| 101 | Switching Protocols | 服务器将按照客户端请求切换协议。 |
| 2xx | 成功状态码 | - |
| 200 | OK | 请求成功。 |
| 201 | Created | 请求已被实现,有一个新的资源已建立。 |
| 204 | No Content | 服务器成功处理了请求,但未返回任何内容。 |
| 3xx | 重定向状态码 | - |
| 301 | Moved Permanently | 请求的资源已永久移动到新位置。 |
| 302 | Found (Moved Temporarily) | 请求的资源暂时从不同的 URI 响应请求。 |
| 304 | Not Modified | 客户端有缓存的资源并验证了其有效性,但未请求的资源未被修改。 |
| 4xx | 客户端错误状态码 | - |
| 400 | Bad Request | 服务器未能理解请求。 |
| 401 | Unauthorized | 请求要求身份验证。 |
| 403 | Forbidden | 服务器已理解请求,但拒绝执行它。 |
| 404 | Not Found | 请求失败,请求的资源未找到。 |
| 405 | Method Not Allowed | 服务器禁止了使用当前 HTTP 方法的请求,常见在跨域请求的 Method 不允许 |
| 5xx | 服务器错误状态码 | - |
| 500 | Internal Server Error | 服务器遇到未曾预料的情况,无法完成请求的处理。 |
| 502 | Bad Gateway | 服务器作为网关或代理,从上游服务器收到无效响应。 |
| 503 | Service Unavailable | 服务器目前无法使用,通常是由于超载或停机维护。 |
HTTPS 加密过程
HTTP 报文默认是明文发送,协议本身不具备加密,极易导致数据泄漏,流量劫持,受到中间人攻击。
HTTPS 工作流程
先放结论,再解释
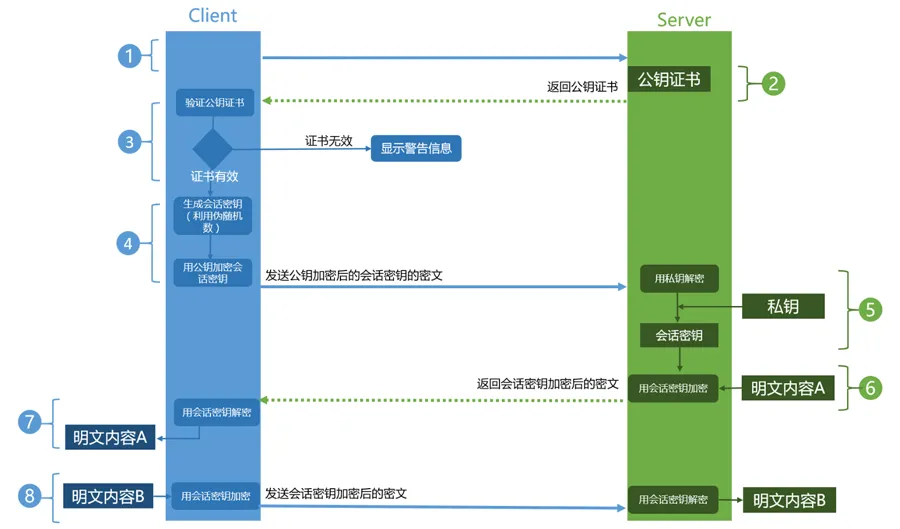
Client发起一个HTTPS的请求,连接443端口,这个过程可以理解成是请求公钥的过程Server端收到请求后,通过第三方机构私钥加密,会把数字证书(也可以认为是公钥证书)发送给ClientClient验证公钥证书,比如是否在有效期内,证书的用途是不是匹配Client请求的站点,是不是在CRL吊销列表里面,它的上一级证书是否有效,这是一个递归的过程,直到验证到根证书(操作系统内置的Root证书或者Client内置的Root证书),如果验证通过则继续,不通过则显示警告信息Client使用伪随机数生成器生成加密所使用的对称密钥,然后用证书的公钥加密这个对称密钥,发给ServerServer使用自己的私钥(private key)解密这个消息,得到对称密钥,至此,Client和Server双方都持有了相同的对称密钥Server使用对称密钥加密明文内容A,发送给ClientClient使用对称密钥解密响应的密文,得到明文内容AClient再次发起HTTPS的请求,使用对称密钥加密请求的明文内容B,然后Server使用对称密钥解密密文,得到明文内容B
注意,并不是每次请求都要经历一次密钥传输验证的过程。服务器会维护一个当前会话的 sessionID,客户端每次请求带上这个 sessionID,服务器匹配到会话密钥,就不需要再重新建立 SSL 连接。
不理解再往下看,已理解就不必了。
对称加密
通信双方都持有同一个密钥,并通过这个密钥进行信息的加解密。
如果这个密钥只有通信双方知道,那自然是极好的。在浏览器到服务器的通信场景里,浏览器首先需要服务器下发告知这个密钥,如果第一步就被劫持了,那后续就裸奔了,加解密都毫无意义。
非对称加密
通信双方持有两个不同的密钥,一个叫公钥,一个叫私钥。用公钥加密的信息必须私钥才能解密,反过来用私钥加密的信息也只有公钥才能解开。
通常是服务端持有私钥,第一步也是要下发公钥给浏览器,那么也会面临公钥下发过程被劫持的情形。此时对于中间人,服务器下发的加密数据是可以被解密的。
对称加密 + 非对称加密
这也是 HTTPS 采用的方式。使用对称加密的好处的加解密效率高,非对称加密的好处是传输内容更加不容易被破解。将两者结合,思路是:
- 浏览器端利用伪随机数,生成会话的密钥,作为后续对称加密的公钥;
- 用【网站的公钥(取自下面要讲的证书)】加密会话密钥,发送给网站服务器;
- 服务器用私钥解密 ,得到会话密钥,即为公钥;
- 后续双方均使用该公钥,对称加解密明文内容传输。
数字证书
单纯的对称加密和非对称加密方式,都无法解决【浏览器获取到网站服务器的可信的公钥】这个问题。
这里就引入了 CA(Certificate Authority)认证机构,网站在使用 HTTPS 之前,需要向 CA 机构申领一份数字证书,包含了【持有者信息、公钥】等。服务器把证书传递给浏览器,浏览器从证书里获取网站的公钥即可。证书就如同身份证,证明“该公钥对应该网站”。那证书传输会不会被篡改呢?
所以这里有引入了数字签名,数字签名是由 CA 机构做到数字证书里的,过程如下:
- CA机构拥有非对称加密的私钥和公钥;
- CA机构对证书明文数据T进行hash;(这里为什么要hash?因为证书内容可能会很长,hash 之后得到固定长度的值,在非对称加密时会更高效)
- 对hash后的值用私钥加密,得到数字签名S。
这样【证书数据 + 数字签名】组成完整的数字证书。
浏览器验证过程:
- 拿到证书,得到明文T,签名S。
- 用CA机构的公钥对S解密(由于是浏览器信任的机构,所以浏览器保有它的公钥,见 PS),得到S’。
- 用证书里指明的hash算法对明文T进行hash得到T’。
- 显然通过以上步骤,T’应当等于S‘,除非明文或签名被篡改。所以此时比较S’是否等于T’,等于则表明证书可信。
- 然后就可以从证书中拿到网站的公钥和持有者信息,进行加密通信了。
PS:浏览器会默认安装一些权威认证机构的根证书,如果其中有 CA 机构的根证书,就可以拿到他的可信公钥了。